Lecture 01 paper-2:The Composable Data Management System Manifesto(P.Pedreira, et al., VLDB 2023)
Abstrct
背景/问题: 数据管理系统DMS不断专业化,细分化,但是软件开发方式(其实指的是数据系统的开发方式)并没有跟上专业话的速度。
带来的后果 文章中叫做solid landscape(信息孤岛), 具体来说就是 每个系统都作为一个整体在维护,文章中称为monoliths(单体架构), 无法复用.
对于开发者来说就是 重复造轮子,每个团队都需要从头开发,从存储层,调度器,执行器,优化器……自己写,其实我觉得说的有点严重,其实我知道的在CMU15445是有提到过写个数据库可以从Postgres或者别的什么数据库开始写的,但是其实文章想突出的就是,孤立是说我从Postgres开始写的数据库里面的东西,别的数据库作为基地开发的数据库就用不了
而对于用户来说,面临着好多种不兼容的SQL, NoSQL方言,每个系统的API, 功能, 语义不相同,都要重复学
所以这篇文章的核心观点就是呼吁大家 统一起来,将DBS分解成可复用,模块化的components(组件), 换句话说就是,他想达到的最终的效果是,对于开发者来说 每个模块专注好一个事情,可以用DuckDB的执行器+Velox的执行计划+Arrow的内存格式,对于user来说,只需要记好一套标准就好
当然文章在Abstract一开始提了一嘴 很多公司的开源项目最近已经开始在不同层面推动模块化
我查了一下,结果如下
| 模块功能 | 开源项目 | 作用 |
|---|---|---|
| 内存格式 | Apache Arrow | 统一列式内存表示 |
| 查询表示 | Substrait | 统一逻辑计划格式 |
| 执行引擎 | Velox、DataFusion、Acero | 可嵌入式、高效的执行器 |
| 存储层 | Parquet、Delta Lake、Iceberg | 标准化数据文件格式 |
| 编排 | Arrow Flight、LakeSoul | 数据通信协议、Lakehouse |
Introduce
由于one size does not fit all的理念,出现了大量专用的数据库,每种数据库只适用于一种workload(工作负载)
但文中提到虽然工作负载,需求,运行环境发生了巨大的改变,但是我们开发数据库的方式没有改变,仍然是垂直整合的大型单体系统(monoliths),也就是说,每个系统都是从头到尾开发的
但是问题是每一个数据库系统其实核心结构都是类似的,文章总结了下面的通用逻辑组件
- a language fontend(语言前端): 将用户输入解释为内部格式
- an intermediate representation(IR, 中间表示): 通常是逻辑查询计划或者是物理查询计划, 用于表示查询的结构
- a query optimizer(查询优化器): 将原始的查询计划变换为更高效的形式
- an execution engine(执行引擎)
- an execution runtime(运行环境)
除此之外,文章也提到不仅逻辑相似,实现这些组件所用的数据结构和算法也大同小异
比如
- 操作型数据库的SQL前端和数据仓库的SQL前端基本一样。
- 传统列式数据库的表达式求值引擎和流处理引擎的求值引擎差异不大。
- 各种数据库中对字符串、日期、数组、JSON 的处理函数也都非常相似。
作者认为,是时候进行paradigm shift(范式转换)了
文中设想将数据库系统拆解为更模块化,可复用的modular stack(组件栈), 可以
- 加快新系统开发速度
- 降低维护成本
- 给用户提供统一体验
- 通过明确模块之间的 API 接口、职责划分,数据库软件将更容易适配新的底层硬件(如 GPU、TPU、FPGA、NPU 等新型加速器),跟上硬件演进
- 特别是对于执行引擎和语言前端来说,不管是transactional systems(事务处理系统), analytic systems(分析型系统), stream processing(流处理系统), machine learning workloads(机器学习系统) 都能提供一致的用户体验和语义
Why Now?
- 云计算的普及和计算与存储的分离 -- 后面这个计算与存储分离实际上就是Paper1提到的Lakehouse的架构
- 由于计算和存储分离,所以只需要关注于计算,所以厂商更加注重服务的交付,这个时候很多开源大数据技术和开放的标准应运而生
- Apache Arrow: 统一内存数据表示; ORC/Parquet: 列式存储格式; Hudi/ Iceberg: 表格数据的增量更新和版本管理
- Velox, Substrait, Ibis这些项目的发展, 这些项目的特点是可以复用已有组件
Contributions
- 强调可组合性的重要性,并认为现在就是推动范式转变的最佳时机
- 总结现有的项目, 重要性/影响, 未来需要改进的地方
- 提出了一个新的可组合数据系统的参考架构,并重点讨论了其中尚未受到足够关注、但对实现模块化和复用至关重要的部分。同时,指出了尚未解决的问题和需要深入研究的方向。
Composability in Data Management
什么是可组合性?
将复杂的系统分成一组组相对独立的小组件,目标让每个组件都能独立工作, 独立开发, 复用, 测试
在开发组件过程中,要尽量把复杂细节藏在内部 , 窄接口
可组合性的好处
- Engineering Efficiency(工程效率提高)
- 不再重复造轮子
- 开发更专注
- Faster innovation(加速创新)
- 大公司: 代码基数小, 减少维护负担,专注新特性
- 小公司: not need to be re-developed, decreases time-to-make.
- Coevolution(软硬件协同进化)
- 当前碎片化严重,硬件厂商很难统一支持数据库加速, 也不赚钱
- 如果统一使用一个“物理层” 就能开发专用芯片
- Better user experience
实现可组合性面临的挑战
- Learning curve(学习曲线): 很多库或框架学习成本高
- Developer bias(开发者偏见): 倾向自己写,不愿意读别人的
- Time-to-market fallacy: 认为自己写个原型就能快速上线
- Close fit(组件不完全适配)
A Modular Data Stack
推动 "模块化数据栈"架构: 这个架构中语言组件和执行组件更解耦
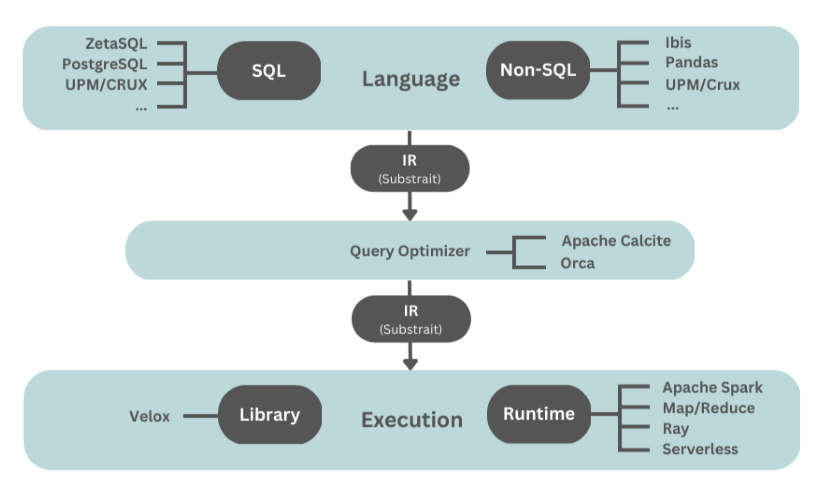
语言组件负责生成IR, SQL, Non-SQL都会通过语言组件转换为IR(中间形式), 而且这个过程是与语言无关,与系统无关的。
生成的IR进入Query Optimizer, Optimizer使用通用框架生成IR fragments(IR片段, 每个IR片段都是可执行的), 这些片段可以独立调度执行
Execution(执行引擎) 处理IR片段, 提高通用且高效的storage primitives(存储原语),如列式格式、行式格式、索引、扫描等
excution runtime负责协调整个系统: 包括 作业部署, 状态监控, 故障处理, 资源管理, 分布式调度
作者的主张是
- 几乎所有的数据系统都可以映射为这种架构,即使某些系统确实某些组件,但整体结构仍然成立
- 不同系统之间的相似性远大于差异性
后面paper中陆续介绍了每部分的现状,主流开源项目,以及如何适配这个模块化数据栈的架构
Language Frontend
前端是最容易实现模块化的部分,输入输出明确,接口简单清晰
目前开源的项目: GoogleSQL -> ZetaSQL, CoreSQL,以及DuckDB复用PostgresSQL的parser,这些项目本质上都使用了C/C++实现的parser(语法分析器)和analyzer(语义分析器),使用了Flex, Bison, ANTLR等工具来构建,都说明开源系统之间共享parser的做法可行。
此过程通常需要实现用于表、列和函数签名解析(用于类型绑定)的API, 类型绑定(type binding), 其实对于Binder, 在CMU15445中就学过,其实就是将词语绑定在数据库实体上,这些实体可能体现为各种C++类, 在这个过程中,对于SELECT name FROM user WHERE age>30;中,系统要知道user表有没有name和age列,age>30是否类型匹配……
除了词法分析(tokenization),语法分析(parsing),类型绑定(type binding),mordern language frontend还需要支持一下功能
- Semantic Types(语义类型)
- Type-checkd Macros(带类型检查的宏)
- IDE Interoperability(IDE互操作性)
- Non-SQL
Semantic Types
传统的数据库的类型如常见的Int, Varchar, Date都是结构层面的数据类型,只要数据类型兼容就会被运行,因为传统的数据库无法知道这些字段的业务含义,而Semantic Types就是数据所负担的语义或者说是业务含义,可以一些不必要的麻烦
Ability1: 避免不同语义的数据类型错误比较
-- 假设 UserID 和 DeviceID 都是 INT 类型
SELECT * FROM logs WHERE UserID = DeviceID;
这个SQL语句的UserID和DeviceID都是int类型,那么这句话在传统数据库中语法是正确的,类型绑定也正确,所以会执行并返回结果
但事实上语义上是错误的,没有比较意义,有了Semantic Types, language frontend就能识别这种语义冲突,在编译器/编写时直接报错或者发出警告, 避免逻辑漏洞
Ability2: 单位不一致导致的错误操作
-- timestamp_ms: 毫秒
-- timestamp_sec: 秒
SELECT * FROM events WHERE timestamp_ms = timestamp_sec;
对于这两个字段都是BIGINT类型,但事实上我们知道一个表示的毫秒一个表示的是秒,加入Semantic Types, Language Frontend的静态检查就会提醒事实上这两个字段的含义表示的单位是不同的
Type Checked Macros
在现代数据库中如BigQuery, Snowflake, Redshift,SQL查询往往非常庞大,特别实在多表连接(join), 多层子查询(nested subqueries), 复杂条件, 多步骤ETL或数据建模中.... 而Language Frontend的一个高级功能是SQL Macro(SQL 宏), 是一种对大SQL查询的一种静态抽象机制
SQL宏有点类似于C/C++中的#define,可以定义一些复杂的重复片段,抽象出来,像模块一样复用,最终会在IR阶段展开称为完整的SQL
IDE Interoperability
language frontend暴露API给IDE使用,IDE插件开发者就能做出更智能的SQL编辑体验,实现Syntax Highlighting(语法高亮), Token Prediction(预测), Static Type Checking(检查), Autocompletion(自动补全), 而实现这些功能的背后 就是parser和analyzer的预测然后通过API传递,以营造出了IDE和数据库使用的是一个language frontend,在IDE中看到的提示,错误,补全和数据库运行时一致
其中,ZetaSQL就被用在Google BigQuery中,提供只能编辑功能
Non-SQL APIs
SQL是一种声明式语言,适合表达要什么,而不是怎么做,所以在机器学习,数据处理等语言或者程序中,SQL并不友好,这其实也是Paper1 Lakehouse所提到的一个问题
其实很大的一个问题是可能是要拼接字符串,我之前写代码就拼接过字符串,其实很麻烦 而且还会出一些问题 比如SQL注入的问题
为了避免拼接SQL字符串,人们设计了DataFrame类似的API(如Pandas, Spark DataFrame, dplyr等, 其实我觉着Springboot中的Mybtis Plus的那种形式也算吧), 通过另一种方法来表示相同的意思和计算
# SQL
SELECT name FROM users WHERE age > 30;
# DataFrame
users.where("age > 30").select("name")
但是现在市面上的Non-SQL APIs有个问题是不兼容,而下面的数据库的方言, 接口 也不同
Ibis这个项目的做法是讲Pandas/ DataFrame风格代码翻译成SQL,但作者认为这种中间人的架构并不是好的解决方案。
好的解决方案是采用统一的IR驱动架构,Spark将SparkSQL和DataFrame(PySpark)都能转换成同一个IR,然后将IR直接传入执行引擎,而执行引擎不需要考虑来源
所以未来ORM(Object-Relational Mapping, 对象映射关系)是否能够绕过SQL,直接转为IR,还是一个需要探索的问题 -- 这个问题的思考方法是这样的现在的ORM是将对象/类自动转换为SQL,然后调用数据库,说白了本质上就是SQL的生成器+封装器,未来执行引擎都只吃统一的 IR,那 ORM / 框架不必再输出 SQL,而可以直接输出 IR, 那么其实ORM框架也会变成一种语言前端
Intermediate Representation
首先需要弄明白的一个点是 什么是Intermediate Representation(IR, 中间表示)?
IR是编译器领域的一个概念,表示程序在被执行之前的一种结构化表示形式,这种表示携带足够的信息,便于后续执行,优化,转换等处理
而IR在数据库系统中的体现就是一种表达式树(Expression Tree)或者叫语法树,其实在CMU15445中我见过逻辑计划和物理计划,尤其是物理计划其实就是在一颗语法树的基础上,包含了很多明确要求执行器怎么做的信息,比如join使用hash join,排序使用什么排序等等
过去,其实现在我感觉也是,市面上的每个数据库系统 不同数据库都在做不同的事情(这也是CMU15445开始的一个核心观点)因此,也并不追求通用性或模块化,但这些IR实际上都差不多,都是一种表达式树,包含
- 函数调用(function calls)
- 表引用(table references)
- 字面量(literals)
- SQL 操作:筛选(filtering)、投影(projection)、排序(ordering)、连接(joining)、聚合(aggregation)、窗口函数(windowing)、分区/打乱(shuffle/repartition)、展开(unnesting)等。
所以Substrait做了一个统一IR的尝试,定义了数据系统的通用功能,明确了哪些是必须遵循的标准,哪些是可选的内容,而且支持自定义
但IR仍然面临一些Challenge
Challenge 1: 将IR作为对外接口(external API)引入系统
如果要允许数据系统执行外部组件生成的IR, IR需要成为系统外部API的一部分,但这就带来了两个问题。
其一是兼容性和版本管理更难,比如在系统A发布了IR1.0版本,后续添加了新操作和语义变更,但是系统B仍然在使用旧版本IR 那旧版本IR也仍需要正常运行
其二是复杂度的上升,IR的表达形式和计算远比SQL API表示的丰富,所以文章中提到了一个点是IR的操作可能会导致暴露潜伏的bug等,所以一些努力试图把IR序列化到SQL语句中来避免这种情况,这个方法其实前面在Language Frontend中也提到过,但是作者仍然认为这种方法并不好,因为他觉得是把很一个大的集合映射进了一个小的集合,SQL方言会限制IR API.
Challenge 2: IR描述性不同, 难以保证语义等价
IR 的描述目前还不够详细,导致跨系统运行时的行为可能不一致。比如论文中提到了一些example
Example 1是integer overflow的问题, 同一个IR在两个系统上的行为完全不同
- 系统A:计算是超过整数范围会自动截断
- 系统B: 同样情况抛异常
Example 2是数组下标的问题
- 系统A数组可能从0开始
- 系统B数组从1开始
不过文章中也提到了Substrait IR能够捕捉到一些系统特征,但是作者认为仍然有一些差异还不知道 所以这一方面仍然是一项挑战
Challenge 3: 函数语义和实现无法统一
现在的问题是不同的系统中的可用函数集是完全不同的,很多函数不同的系统中名字一样但是语义也不一样,比如说所有系统都有map_entries() 函数, parkSQL 的版本:对 {"a":1, "b":2} 返回 [("a",1),("b",2)], 另一个系统可能返回的是[("b",2),("a",1)](顺序不同),甚至有的系统空map会抛异常
文中认为正确的做法是通过全局url和版本号来识别函数,url控制函数的名称,以及所引用的一些基本实现,比如SparkSQL, 124版本中的map_entries()函数,用spark://functions/map_entries@v124 来表示
Query Optimization
Query Optimization是一个高度研究又多样化的领域,虽然市面上大多数是针对目标数据库系统定制的,但与构建可扩展和可组合的查询优化器相关的工作量很大。
goal: Extensiblity(可扩展性), Composability(可组合性)
Goal 1: Extensiblity -- provide abstractions(提供抽象) and integration hooks(集成挂钩) -- 能够方便的添加新的规则和新的逻辑
Goal 2: Composability -- 使优化器更容易移植到不同的系统
现有的代表性优化器: Orca, Apache Calcite
Orca(Greenplum 开源的PostgreSQL扩展)
优化器和执行引擎之间用XML表达语句分开,模块化,可重用,逻辑和执行解耦。但事实上在非PostgreSQL系统集成很困难
Apache Calcite
被多个系统集成: Hive(大数据SQL系统), Phoenix(基于HBase的关系型接口), Flink/Samza(流处理系统),Qubole(商业数据平台)
但Calcite是Java写的,不适合嵌入非Java系统, 而很多系统事实上使用C++, Rust, Go写的
Execution Engine
什么是Execution Engine?
Execution Engine是真正查询的部分,接收IR作为输入,并利用底层硬件资源执行实际的数据处理任务
比如一个SQL语句
SELECT name FROM users WHERE age > 30 ORDER BY age;
事实上执行的流程是: SQL -> 转为IR -> 进入执行引擎
执行引擎进行user表扫描,条件过滤(age>30), 排序(order by age), 输出结果
执行引擎内部有各种算子(operators)或者叫原语(primitives)
| 操作类型 | 示例 |
|---|---|
| 表扫描 / 索引扫描 | table scan, index scan |
| 表间数据交换 | shuffle, exchange |
| 数据变换 | expression evaluation(如 age + 1) |
| 过滤 | WHERE 子句 |
| 排序 | ORDER BY |
| 连接 | JOIN |
| 聚合 | GROUP BY |
| 展开 | UNNEST |
但现在的问题是不同的数据库系统的执行引擎各不相同,文中用了一句很严重的话
no two systems share the same execution codebase.
没有两个系统共享相同的执行代码库,所以说执行层的碎片化是很严重的,所以组织维护需要考虑的东西就特别多,需要考虑到所有引擎的情况
文中举了一个例子,Meta发现内部有12个不同版本的substr()实现,但是论文并没有列出列出这12种实现是啥,只是简单说明了有的系统字符串的下标从1开始,有的从0开始,有的不允许空字符串等等,但是如果真要了解这12张不同的版本,文章中也标出了引用的来源,可以去看看
可组合执行引擎需要具备哪些能力?
- 接收IR并提供本地执行的方法
- Extensibility APIs(插件式扩展的接口)
其实在文中提到了两类Extensibility APIs
第一类涉及的是执行引擎的底层和数据处理管道的问题,其实就是数据在哪,怎么读写的问题,让执行引擎可以支持不同数据源,不同存储格式…… 我们可以添加一个数据插件直接读取Amazon S3的ORC文件,也可以插入一个插件 添加一个自定义列式存储的读写支持等等
第二类涉及的是SQL语义层,也就是数据怎么处理,语义怎么扩展的问题,让用于可以自定义专属的数据类型,自定义函数,新的运算符等等
但是文中提到了IR仍然会导致大量组件的重复造轮子,比如所有执行引擎都要定义
- memory layout(内存布局): 大多数标准都是用Apache Arrow
- local resource management(本地资源管理): 包括内存池分配与释放策略,SSD缓存策略,CPU核心分配等等问题
- Encoding/Decoding: 编码格式的问题,所有系统几乎都要支持Rarquet, ORC, CSV, JSON...
所以文中提到的方法是要聚焦于更细粒度的可组合执行,不在把执行引擎当做一个整体进行开发,而是再拆成更小的模块,然后使用一个统一的库作为common local execution bus(通用执行总线)将每个模块连起来,互相通信
开发过程中两个必须遵循的核心原则是: performance equivalence(性能等价性), innovation must not be hindered(不阻碍创新), 其中性能等价性是指组合的执行引擎和单个执行引擎版本的性能应该是一样的,文中提到了可以通过热代码路径之外来实现API传递和调用,具体是说,将API设计在低频调用的地方,比如每个查询调用一次,每个数据批次调用一次,而不要设计在每条记录调用一次的地方,将跨越组件边界相关的成本摊销掉
从硬件角度来看,现在的硬件角度晶体管密度增长放缓,单核性能提升困难(这个观点其实在CSAPP中提到过), 为了防止摩尔定律的终结,现代系统开始依赖硬件加速器来获得性能突破。比如说GPU,FPGA,TPU等等
但是问题在于现在不可能给每种执行引擎适配各种硬件,也不可能基于硬件重造执行引擎
所以一个好的解决方案就是构建统一的执行引擎,将常用的复杂的操作符通过硬件定制来实现加速,其余操作继续使用CPU实现,这样其实只需要专门对标构建一种GPU加速引擎就都能用
最后这一部分介绍了Velox, 一个为数据管理系统提供统一执行引擎的第一个大型开源项目, 简单来说,是一个通用,可嵌入,可扩展,跨SQL方言,支持硬件加速的统一框架,在Presto, Spark分析型查询引擎,流处理平台,数据仓库等等都适用。
Execution Runtime
Execution Runtime(执行运行时) 是 支撑执行引擎(比如 Velox、Photon)实际运行任务的“底层平台” 主要负责
- 任务调度(scheduling):决定哪些任务在哪里、何时运行。
- 资源分配(resource allocation):分配内存、CPU 核数、网络带宽等资源。
- 任务隔离(containerization & isolation):多个用户或任务之间要相互隔离,避免资源冲突。
- 通信管理(communication):尤其在分布式系统中,节点间需要发送/接收数据(比如 shuffle 阶段)。
其实我不大懂shuffle是啥,之前一直没看完CMU15445的最后那个关于distributed的lecture.
我查了一下shuffle(洗牌) 就是在分布式计算过程中,把数据从一个节点重新分发到其他节点,以便进行下一阶段的处理,有点像打乱重分配,比如每个机器会看到多个user_id的数据
节点A:user1, user2, user3
节点B:user2, user3, user4
为了将对应的user_id汇总统计,就会让相同的key都跑到同一台机器上
所以说Execution Runtime就是将每个任务都调度好,多个用户提交任务的时候,Runtime需要做好“隔离”, 而这个隔离的手段,有的用cgroups, Docker容器做资源隔离,有的用线程做隔离……而这个过程在分布式环境下会更复杂,需要将查询拆分成多个task, 分发到多个节点(worker)运行,节点之间进行shuffle, 广播,汇总
文中还提到了Runtime的发展历史
| 时代 | 框架 | 特点 |
|---|---|---|
| MapReduce | Hadoop | 只能支持 Map → Shuffle → Reduce |
| DAG 计算模型 | Spark、Tez | 可表示任意任务图,更灵活 |
| 任意函数执行模型 | Ray、Dask | 可执行任意函数,适合 Python/ML |
| 流处理 | Flink、Spark Streaming | 实时数据处理,低延迟,事件驱动 |
整个趋势就是解耦执行引擎和Runtime
传统的结构,可能是Spark引擎+JVM Runtime紧密耦合,而现代架构Spark 仍然用 Java 写的 DAG Scheduler,但底层执行逻辑由 C++ 引擎 Velox 或 Photon 处理
调度器Scheduler的接口相对成熟,系统可以自由选择调度方式
- Apache YARN:最早为 Hadoop 提供调度,后来支持 Spark、Flink、Tez 等
- Kubernetes:现代容器调度平台,也支持 Spark-on-K8s、Ray-on-K8s 等
而其他部分仍然缺乏标准,比如上面也提到了每个系统的隔离机制不同,有的用docker,有的用线程;shuffle有的直接写磁盘(Spark), 有的用流(Flink)
作者认为,Serverless Computing和Worker-as-a-Service是下一代机会
Serverless(无服务器)计算并不是真的没有服务器而是用户不需要管理服务器,只需要编写业务逻辑代码,平台自动处理资源调度,扩容缩容,任务运行,监控等基础设施操作
Worker-as-a-Service 是一种更具体的 serverless 模型,指的是把执行节点当做微服务动态分配:
- 数据处理系统的 计算 Worker 被当作服务随用随起;
- 每次提交查询或任务时,平台会临时起一个或多个 worker 来执行,再自动销毁。